So optimieren Sie Einzelseiten-Sites für Suchmaschinen
Wenn Google und andere Suchmaschinen Websites indexieren, führen sie kein JavaScript aus. Dies scheint zu bewirken, dass einzelne Seiten, von denen viele auf JavaScript basieren, im Vergleich zu einer traditionellen Website einen enormen Nachteil haben.
Nicht auf Google zu sein, könnte leicht den Tod eines Unternehmens bedeuten, und diese entmutigende Fallstricke könnte die Uninformierten dazu verleiten, einzelne Seiten-Websites ganz aufzugeben.
Allerdings haben einzelne Seiten einen Vorteil gegenüber herkömmlichen Websites in der Suchmaschinenoptimierung (SEO), weil Google und andere die Herausforderung erkannt haben. Sie haben einen Mechanismus für einzelne Seitenwebsites entwickelt, um nicht nur ihre dynamischen Seiten indizieren zu lassen, sondern auch ihre Seiten speziell für Crawler zu optimieren.
In diesem Artikel konzentrieren wir uns auf Google, aber andere große Suchmaschinen wie Yahoo! und Bing unterstützen denselben Mechanismus.
Wie Google eine einzelne Seitenwebsite crawlt
Wenn Google eine herkömmliche Website indiziert, scannt und indiziert der Web-Crawler (Googlebot) zuerst den Inhalt des URI der obersten Ebene (z. B. www.myhome.com). Sobald dies abgeschlossen ist, folgt es allen Links auf dieser Seite und indiziert diese Seiten ebenfalls. Es folgt dann den Links auf den folgenden Seiten und so weiter. Schließlich indiziert es den gesamten Inhalt der Site und der zugehörigen Domänen.
Wenn der Googlebot versucht, eine einzelne Seitenwebsite zu indizieren, wird nur ein einzelner leerer Container (normalerweise ein leeres div- oder body-Tag) angezeigt. Es gibt also nichts zu indexieren und keine Links zu crawlen, und die Website wird entsprechend indiziert ( in der runden runden "Mappe" auf dem Boden neben seinem Schreibtisch).
Wenn das das Ende der Geschichte wäre, wäre dies das Ende von einzelnen Seiten für viele Webanwendungen und Websites. Glücklicherweise haben Google und andere Suchmaschinen die Bedeutung einzelner Seiten erkannt und Tools bereitgestellt, mit denen Entwickler Suchinformationen für den Crawler bereitstellen können, die besser sein können als herkömmliche Websites.
Wie man eine einzelne Seite site crawlable macht
Der erste Schlüssel zum Crawling unserer Website mit einer einzelnen Seite besteht darin, zu erkennen, dass unser Server feststellen kann, ob eine Anfrage von einem Crawler oder von einer Person, die einen Webbrowser verwendet, erfolgt und entsprechend reagiert. Wenn unser Besucher eine Person ist, die einen Webbrowser verwendet, antworten Sie wie gewohnt, aber für einen Crawler geben Sie eine Seite zurück, die so optimiert ist, dass der Crawler genau das zeigt, was wir möchten, in einem Format, das der Crawler leicht lesen kann.
Wie sieht eine Crawler-optimierte Seite für die Startseite unserer Website aus? Es ist wahrscheinlich unser Logo oder ein anderes primäres Image, das wir in den Suchergebnissen sehen möchten, ein SEO-optimierter Text, der erklärt, was die Site ist oder tut und eine Liste von HTML-Links zu nur den Seiten, die Google indexieren soll. Was die Seite nicht hat, ist ein CSS-Stil oder eine komplexe HTML-Struktur, die darauf angewendet wird. Es enthält auch kein JavaScript oder Links zu Bereichen der Website, die Google nicht indizieren soll (z. B. rechtliche Haftungsausschluss-Seiten oder andere Seiten, die nicht durch eine Google-Suche betreten werden sollen). Das Bild unten zeigt, wie eine Seite einem Browser (links) und dem Crawler (rechts) präsentiert werden kann.
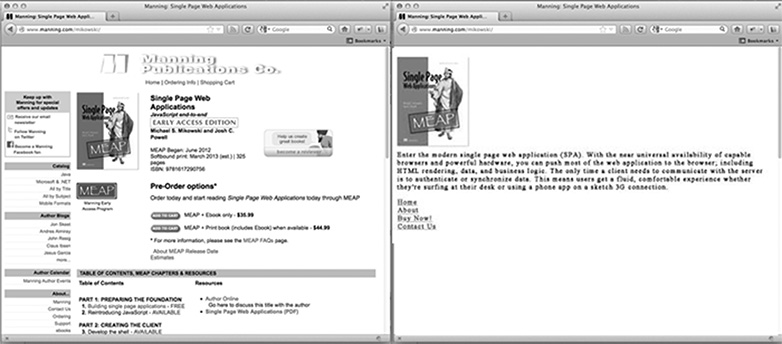
Anpassen des Inhalts für Crawler
In der Regel verlinken einzelne Seiten mit einem Hash-Knall (#!) Zu unterschiedlichen Inhalten. Diese Links werden von Menschen und Crawlern nicht auf die gleiche Weise verfolgt.
Wenn beispielsweise auf unserer Seite mit einer einzelnen Seite ein Link zur Benutzerseite wie /index.htm#!page=user:id123 aussieht, würde der Crawler das #! und wissen, nach einer Webseite mit dem URI /index.htm?_escaped_fragment_=page=user:id123 zu suchen. Da der Crawler dem Muster folgt und nach diesem URI sucht, können wir den Server so programmieren, dass er auf diese Anfrage mit einem HTML-Snapshot der Seite reagiert, der normalerweise von JavaScript im Browser gerendert wird.
Dieser Schnappschuss wird von Google indiziert, aber jeder, der auf unseren Eintrag in den Google-Suchergebnissen klickt, wird nach /index.htm#!page=user:id123 weitergeleitet . Die Single-Page-JavaScript wird von dort übernehmen und die Seite wie erwartet rendern.
Dies bietet Entwicklern von Einzelseiten-Websites die Möglichkeit, ihre Website speziell für Google und speziell für Nutzer anzupassen. Anstatt einen Text zu schreiben, der für eine Person lesbar und attraktiv ist und für einen Crawler verständlich ist, können Seiten für jeden optimiert werden, ohne sich um den anderen kümmern zu müssen. Der Crawler-Pfad durch unsere Website kann kontrolliert werden, sodass wir Nutzer von Google-Suchergebnissen auf bestimmte Einstiegsseiten verweisen können. Dies erfordert mehr Arbeit seitens des Ingenieurs zu entwickeln, aber es kann große Gewinne in Bezug auf die Suchergebnisposition und Kundenbindung haben.
Den Web Crawler von Google erkennen
Zum Zeitpunkt der Erstellung dieses Artikels kündigt sich der Googlebot als Crawler für den Server an, indem er Anfragen mit einer User-Agent-Zeichenfolge von Googlebot / 2.1 (+ http://www.googlebot.com / bot.html) abgibt . Eine Node.js-Anwendung kann nach dieser User-Agent-Zeichenfolge in der Middleware suchen und die Crawler-optimierte Homepage zurücksenden, wenn die User-Agent-Zeichenfolge übereinstimmt. Ansonsten können wir die Anfrage normal bearbeiten.
Diese Anordnung scheint zu kompliziert zu sein, da wir keinen Googlebot besitzen. Google bietet jedoch einen Dienst für öffentlich verfügbare Produktionswebsites an als Teil seiner Webmaster-Tools, aber ein einfacherer Weg zum Testen besteht darin, unsere User-Agent-Zeichenfolge zu fälschen. Früher erforderte dies einige Befehlszeilen-Hacker, aber Chrome Developer Tools machen dies so einfach wie das Klicken auf eine Schaltfläche und das Aktivieren eines Kontrollkästchens:
Öffnen Sie die Chrome-Entwicklertools, indem Sie auf die Schaltfläche mit drei horizontalen Linien rechts neben der Google Toolbar klicken und dann im Menü Tools auswählen und auf Entwicklertools klicken .
In der rechten unteren Ecke des Bildschirms befindet sich ein Zahnrad-Symbol: Klicken Sie darauf und sehen Sie einige erweiterte Entwickleroptionen, z. B. Deaktivieren des Cache und Aktivieren der Protokollierung von XmlHttpRequests.
Klicken Sie auf der zweiten Registerkarte mit der Bezeichnung " Überschreibungen" auf das Kontrollkästchen neben der Bezeichnung " Benutzeragent " und wählen Sie eine beliebige Anzahl von Benutzeragenten aus der Dropdown-Liste von Chrome, Firefox, IE, iPads und mehr aus. Der Googlebot-Agent ist keine Standardoption. Um es zu verwenden, wählen Sie Andere und kopieren Sie die User-Agent-Zeichenfolge und fügen Sie sie in die bereitgestellte Eingabe ein.
Jetzt spoofiert sich dieser Tab selbst als Googlebot und wenn wir irgendeinen URI auf unserer Site öffnen, sollten wir die Crawlerseite sehen.
Abschließend
Offensichtlich haben unterschiedliche Anwendungen unterschiedliche Anforderungen in Bezug darauf, was mit Webcrawlern zu tun ist, aber es ist wahrscheinlich nicht ausreichend, dass immer eine Seite an den Googlebot zurückgegeben wird. Außerdem müssen wir entscheiden, welche Seiten wir veröffentlichen möchten und wie unsere Anwendung den _escaped_fragment_ = key = value- URI dem Inhalt zuordnen kann , den wir ihnen zeigen möchten.
Vielleicht möchten Sie die Server-Antwort in das Frontend-Framework einbinden und binden, aber ich nehme hier den einfacheren Ansatz und erstelle benutzerdefinierte Seiten für den Crawler und lege sie in eine separate Router-Datei für Crawler.
Es gibt auch eine Menge legitimerer Crawler da draußen. Sobald wir unseren Server für den Google-Crawler angepasst haben, können wir ihn erweitern, um sie ebenfalls einzubinden.
Erstellen Sie einzelne Seitenwebsites? Wie funktionieren einzelne Seiten in Suchmaschinen? Lass uns deine Gedanken in den Kommentaren wissen.
Ausgewähltes Bild / Vorschaubild, Bild suchen über Shutterstock.